25 Jun 2026 Performance GPU Rent Best GPU for AI Inference in 2026: Quick Picks by Workload and Budget Find the best GPU for AI inference with quick picks by workload, budget, model size, and deployment needs.
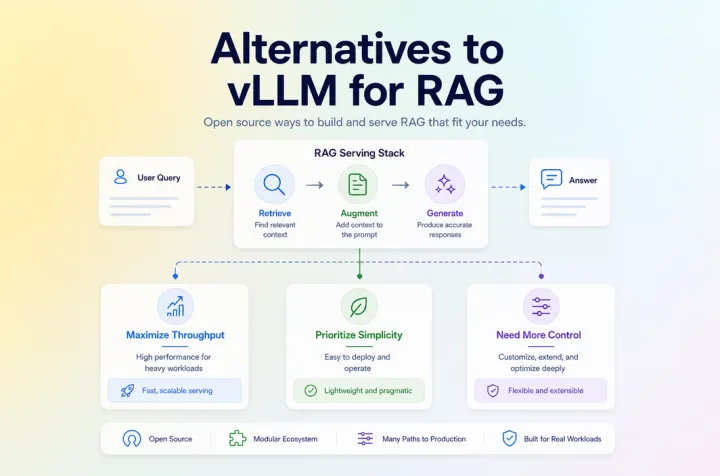
25 Jun 2026 Using Cases Cloud GPU Open-Source Alternatives to vLLM for RAG Workloads Compare open-source alternatives to vLLM for RAG by throughput, deployment complexity, and workflow fit so teams can choose the right stack.
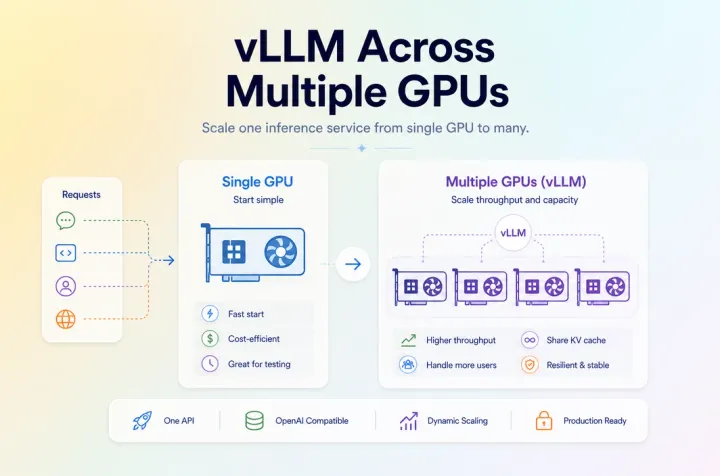
25 Jun 2026 Cloud GPU GPU Rent Performance vLLM Serve Multiple GPUs: When to Scale Beyond One GPU Learn when vLLM should serve across multiple GPUs, what bottlenecks appear first, and how to choose the right deployment path for scaling.
07 May 2026 SGLang vs vLLM: Which LLM Serving Framework Should You Use? Comparing SGLang vs vLLM? See how they differ on serving architecture, runtime features, deployment fit, and production GPU infrastructure.