Key Takeaways
- Teams searching for open-source alternatives to vLLM for RAG are usually making a stack-selection decision, not looking for a casual framework list.
- The best alternative depends on which part of the RAG serving path is under pressure: throughput, simplicity, hardware efficiency, or deployment control.
- The most useful comparison is one that evaluates alternatives by
Best For,Caveat, and RAG workflow fit instead of treating every open-source inference stack as interchangeable. - RunC.ai fits this topic best as the deployment environment where teams can test and operate whichever inference stack actually matches their workload.
Introduction

vLLM is a strong default in many LLM serving conversations, but RAG teams do not always need the exact same tradeoffs. Some teams want simpler deployment. Some want a different performance profile. Some care more about hardware efficiency, integration style, or infrastructure control than about using the most popular serving name in the current cycle. For open source alternatives to vllm rag, the real decision is which stack makes the most sense for a specific RAG system and what tradeoffs come with switching.
The right answer starts by comparing what part of the serving layer actually matters most. That shift is important because many “alternatives” roundups stay too shallow. They list names, add a few surface-level claims, and never connect the comparison back to the actual RAG serving workflow. For this keyword, readers usually need practical help choosing.
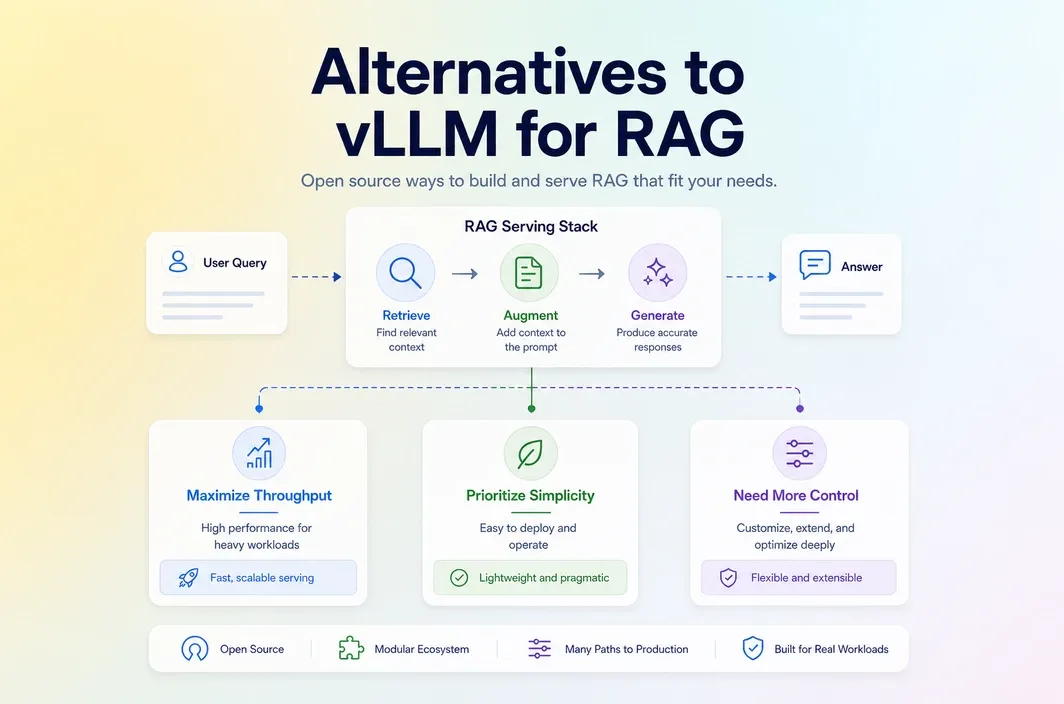
What to Compare When Choosing a vLLM Alternative for RAG
RAG serving is not only about raw token generation speed. It is a full workflow that sits between retrieval, prompt assembly, model execution, and production behavior. That means the best vLLM alternative depends on more than benchmark intuition. For open source alternatives to vllm rag, the real question is which serving stack matches the rest of the pipeline cleanly. The first comparison point is throughput versus simplicity. Some teams want maximum serving performance and are comfortable paying for more infrastructure discipline. Others need a fast path to production with fewer moving parts.
The second comparison point is hardware fit. Some stacks are more attractive when GPU efficiency is the main problem. Others are more attractive when operational predictability matters more than squeezing every last bit of performance out of the deployment. The third comparison point is integration flexibility. A team building a small RAG API and a team building a complex internal platform may end up choosing different serving layers even if they use similar models.
There is also a fourth comparison point that matters more in RAG than in many plain text-generation use cases: how forgiving the stack is once retrieval, re-ranking, prompt assembly, and serving all have to work together. A stack that looks excellent in isolation can still be awkward if it creates too much operational weight around the rest of the application.
| What to compare | Why it matters for RAG |
|---|---|
| Serving throughput | Impacts latency and concurrency under retrieval-heavy traffic |
| Deployment complexity | Changes how quickly the team can move from testing to production |
| GPU efficiency | Affects cost-performance for repeated inference |
| Integration style | Decides whether the stack fits the surrounding application architecture |
| Operational control | Matters more as the RAG system becomes a maintained product |
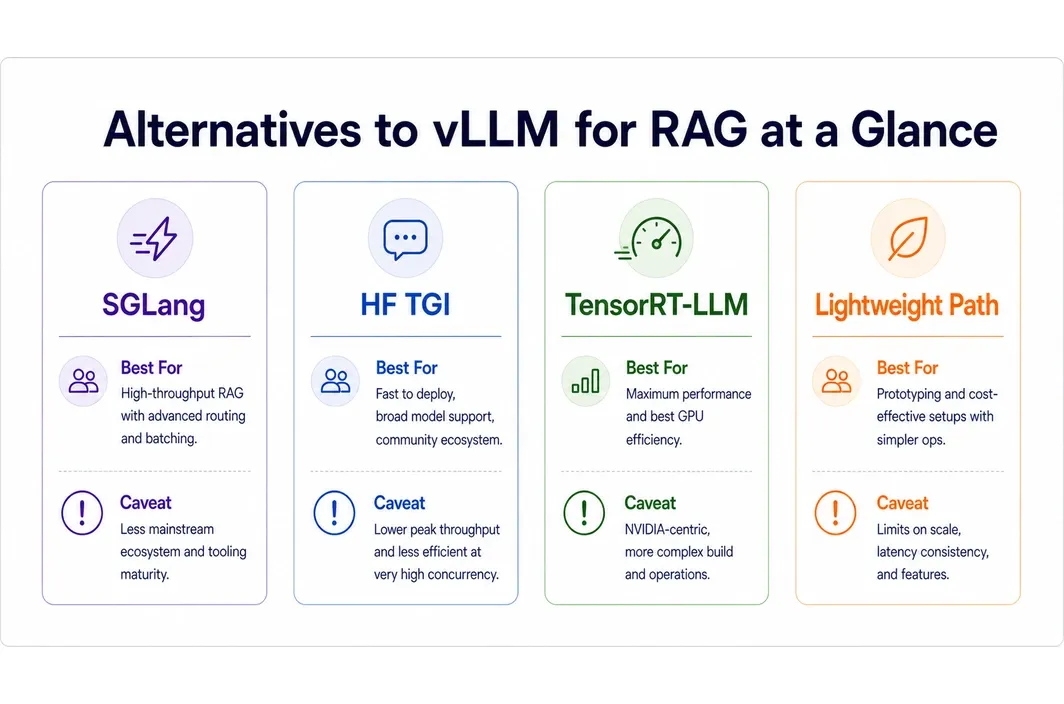
| ## Best Open-Source Alternatives to vLLM for RAG Workflows |
SGLang is a strong candidate when the team is actively optimizing serving behavior and wants an alternative that still lives close to modern high-performance inference workflows. It is most relevant for teams that want to push performance while staying in an open-source ecosystem. The caveat is that a more performance-oriented stack can still require stronger infra discipline. Hugging Face Text Generation Inference is attractive when a team values a more established serving path with familiar ecosystem touchpoints. It is often easier to justify in environments that already use Hugging Face tooling heavily. The caveat is that “familiar” does not automatically mean “best fit” for every RAG deployment style.
TensorRT-LLM becomes relevant when performance optimization is the central issue and the team is comfortable with a more specialized serving path. It is not the universal answer, but it belongs in the conversation when throughput and hardware optimization dominate the choice. LMDeploy and similar serving paths are worth considering when the team wants a different balance between performance, deployment experience, and model support. The main caveat is that the team should validate ecosystem fit rather than choosing an alternative just because it is less common.
Lighter-weight options such as llama.cpp-style server deployments can also matter for smaller or more constrained RAG setups. They are not drop-in replacements for every production path, but they can be valuable when simplicity or narrower deployment targets matter more than maximum serving scale. Not every open-source serving framework belongs on the shortlist. The practical goal is to eliminate bad-fit options faster.
When vLLM Still Wins
It is also important to say clearly when switching is unnecessary. In many cases, vLLM still wins because it already solves the throughput and serving shape the team actually needs. The problem may not be the framework at all. It may be weak deployment design, poor GPU sizing, or a mismatch between traffic expectations and infrastructure. That is especially true for teams that are still small. Switching stacks too early can create more migration cost than benefit. If vLLM already fits the workload and the team understands how to operate it, the smarter move may be to improve deployment discipline rather than hunt for a different serving layer.
That kind of clarity matters because “alternative” does not automatically mean “upgrade.”
Which Stack Fits Which RAG Team
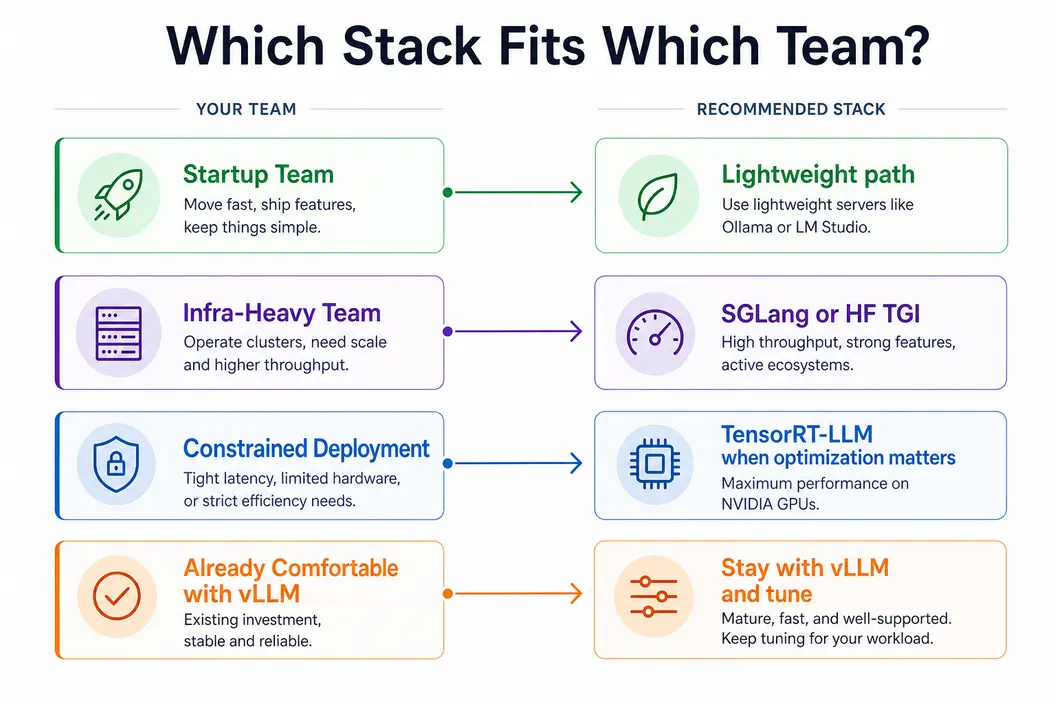
This comparison becomes most useful when mapped to actual team profiles. A startup team with a relatively simple RAG product may value deployment speed and operational clarity more than absolute serving optimization. A more infra-heavy team may be willing to accept a steeper setup curve for stronger control or deeper performance tuning. A team with lighter edge-style constraints may prefer a narrower serving option that keeps the footprint smaller. A platform team running higher concurrency may prioritize a stack that makes scaling behavior more predictable.
Another useful lens is team cognition. Some stacks are reasonable only if the team is comfortable debugging a more complex inference layer. Others are attractive because they reduce cognitive overhead even if they are not the absolute most optimized option on paper.
| Team profile | Likely better fit |
|---|---|
| Startup needing fast deployment | Simpler, better-known serving path |
| Infra-heavy team optimizing performance | More tunable high-performance alternative |
| Smaller constrained deployment | Lightweight serving option |
| Team already comfortable with vLLM | Stay unless another stack solves a specific pain point |
| ## How RunC.ai Helps Teams Test and Deploy RAG Inference Stacks |
RunC.ai fits best here as the environment for comparison and execution. That matters because choosing a stack is only half the decision. The team also needs a place to run the stack on the right GPU tier, keep artifacts organized, and turn experiments into a repeatable serving workflow. GPU Pods are the most natural product angle because they support persistent inference environments, repeated deployment, and infrastructure reuse. That is especially useful when the team wants to compare vLLM against another stack without rebuilding the full environment from scratch each time.
This is also where cost-performance matters. Many RAG teams are still trying to learn whether their bottleneck is model-serving cost, retrieval orchestration, or pure deployment friction. A cost-effective GPU environment helps answer that question faster. That is the right level of product insertion for this topic. RunC is not the answer to “which open-source serving framework is best?” RunC is the answer to “where can the team test and operate the framework that turns out to be the best fit?”
FAQ
What is the best open-source alternative to vLLM for RAG?
There is no single best answer across every team. The right alternative depends on whether your priority is throughput, deployment simplicity, hardware efficiency, or infrastructure control.
Should I switch away from vLLM if my RAG workload is still small?
Usually not by default. If the workload is still small, the migration cost can outweigh the benefit unless another stack solves a specific problem more cleanly.
Which inference stack is easiest to deploy for a startup RAG product?
The easiest path is usually the one that balances serving quality with operational clarity. Simpler deployment often beats theoretical peak performance when the team is still moving fast.
How should I compare throughput and operational complexity across open-source serving stacks?
Compare them against the actual traffic and retrieval pattern of your product. A stack that looks stronger on paper may still be the wrong choice if it adds operating weight your team does not need.
Conclusion
Choosing an open-source alternative to vLLM for RAG is really about choosing the right serving tradeoff. Start by identifying the pressure point in your current system. If the issue is deployment simplicity, choose accordingly. If the issue is throughput or hardware efficiency, compare the more performance-oriented options seriously. If vLLM already fits, do not switch just to follow tool churn. The most useful next step for open source alternatives to vllm rag is to test the top-fit stack in a RunC.ai GPU environment that matches your expected workload, then decide from evidence instead of framework fashion.

Member discussion: