
Key Takeaways
vLLMis still the default starting point for many teams because it is widely adopted, easy to get running, and strongly associated with high-throughput LLM serving.SGLangis increasingly compelling when you care about aggressive serving optimizations, structured outputs, multimodal support, and lower-level serving control.- Both frameworks expose OpenAI-compatible APIs, so the practical decision often comes down to feature fit, operational preference, and model support rather than API style alone.
- The best choice is usually workload-specific:
vLLMfor broad default adoption,SGLangfor teams that want deeper serving-system optimization or more specialized features. - If you plan to deploy either framework in production, the infrastructure choice still matters. RunC.ai fits this topic through GPU Pods, high-memory GPU options, and storage features that support repeatable LLM serving setups.
If you are comparing SGLang vs vLLM, you are probably not looking for a generic “what is LLM inference?” article. You are likely trying to decide which serving framework is the better fit for a real deployment, whether that means a single-GPU API server, a production inference cluster, or a multimodal serving stack.
That makes this a practical comparison, not just a feature roundup. Both SGLang and vLLM are serious open-source serving systems with OpenAI-compatible interfaces, modern inference optimizations, and strong momentum. The difference is in what each project emphasizes and how those choices affect deployment.
What SGLang and vLLM Are Actually Trying to Optimize
At a high level, both frameworks try to solve the same business problem: serving LLMs efficiently under real latency and throughput constraints. But they do not present themselves in exactly the same way.
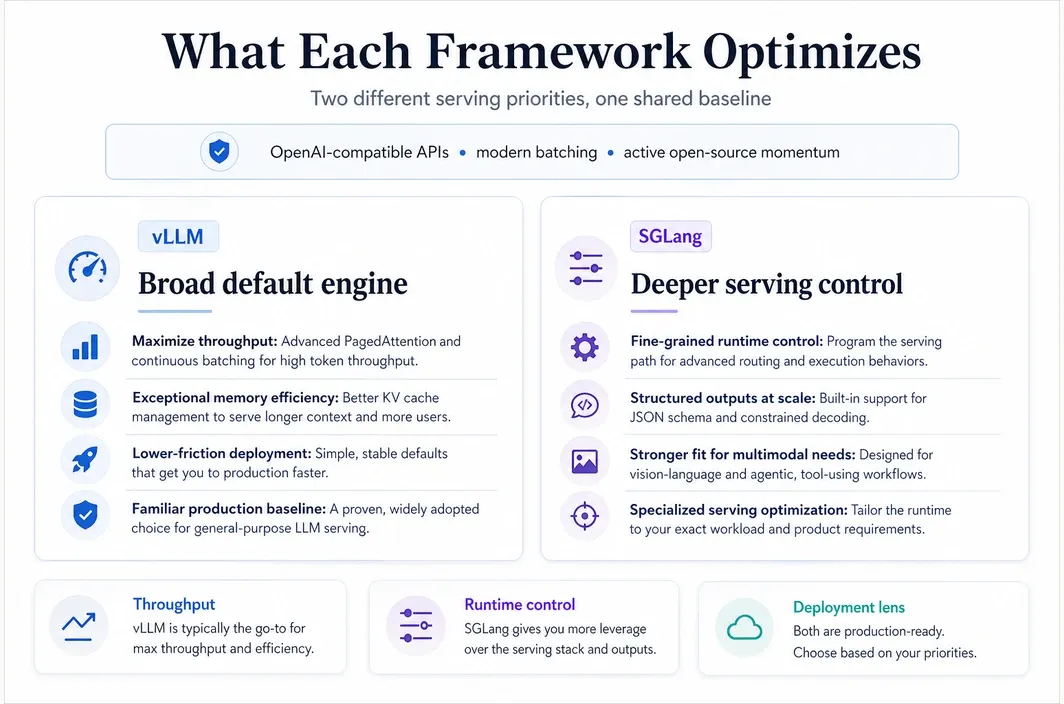
The current vLLM documentation emphasizes fast, memory-efficient inference and serving, with PagedAttention, continuous batching, chunked prefill, prefix caching, quantization, speculative decoding, and disaggregated serving features. The project also highlights ease of use as a core design goal.
SGLang presents itself as a high-performance serving framework for large language models and multimodal models. Its current documentation and repository emphasize RadixAttention for prefix caching, a zero-overhead CPU scheduler, prefill-decode disaggregation, continuous batching, structured outputs, quantization, multi-LoRA batching, and broad hardware support across GPUs, TPUs, and other accelerators.
| Framework | Core Emphasis | What That Means in Practice |
|---|---|---|
| vLLM | High-throughput, memory-efficient LLM serving with broad adoption | Strong default choice when you want a mature serving engine with familiar deployment paths |
| SGLang | High-performance runtime plus more aggressive serving-system optimization and multimodal orientation | Attractive when you want deeper serving features, structured generation focus, or more specialized runtime behavior |
That difference matters because teams often choose a serving framework based not only on benchmark claims, but also on how easily the system fits their operating style.
SGLang vs vLLM on Architecture and Runtime Features
vLLM is still best known for PagedAttention, which remains its signature memory-management idea. Its official materials now position it as a broader serving engine built around throughput, efficient KV-cache handling, continuous batching, prefix caching, graph optimizations, quantization, and support for disaggregated serving.
SGLang, by contrast, promotes a wider cluster of runtime techniques right in its project description: RadixAttention, a zero-overhead CPU scheduler, continuous batching, paged attention, chunked prefill, structured outputs, speculative decoding, prefill-decode disaggregation, and parallelism strategies across multiple dimensions.
| Comparison Area | vLLM | SGLang |
|---|---|---|
| Signature concept | PagedAttention | RadixAttention |
| Main positioning | Efficient, high-throughput LLM serving engine | High-performance serving framework for LLMs and multimodal models |
| Prefix reuse story | Automatic prefix caching | RadixAttention for prefix caching |
| OpenAI-compatible APIs | Yes | Yes |
| Structured outputs | Supported | Supported and emphasized prominently |
| Multimodal positioning | Supported in current architecture and docs | Built into project positioning and model support story |
| Scheduler/runtime emphasis | Throughput, batching, cache efficiency, graph optimizations | Scheduler efficiency, runtime control, structured serving, multimodal breadth |
The practical takeaway is that neither project is “basic” anymore. Both have moved well beyond a simple inference wrapper. The difference is how opinionated their strengths feel. vLLM often reads like the broad default engine for modern LLM serving. SGLang reads more like a framework for teams that want more control over advanced runtime behavior.

Which One Is Easier to Deploy and Operate?
For many teams, this is the real question behind SGLang vs vLLM. The decision is not only about architecture. It is about how quickly you can get the system running, how predictable the deployment path feels, and how much specialized tuning you are willing to absorb.
The vLLM design thesis explicitly emphasizes ease of use. Its formal design write-up describes simplicity and low-friction deployment as one of its guiding goals. That matters because a serving system is often chosen by infra teams that need fast time-to-first-deployment, not just maximum theoretical efficiency.
SGLang is not difficult in the abstract, but its current presentation puts more visible weight on advanced runtime behavior and optimization knobs. That can be a strength if you know exactly why you want those capabilities. It can also mean the learning curve feels steeper when your team simply wants a robust general-purpose serving layer.
| Team Situation | Better Default Starting Point | Why |
|---|---|---|
| You want the safest mainstream default for LLM serving | vLLM | Its adoption, documentation surface, and ease-of-use philosophy make it the lower-friction default |
| You want deeper serving optimization and more explicit runtime features | SGLang | It foregrounds scheduler and runtime behavior more aggressively |
| You expect multimodal or structured-serving needs to matter early | SGLang | Its project positioning leans more directly into those areas |
| You want a broad and familiar deployment choice for standard text inference | vLLM | It remains the most common comparison baseline in production LLM serving |
This is one reason many teams begin with vLLM, then re-evaluate once their workloads become more specialized. Others start with SGLang because they already know their workloads will benefit from its runtime priorities.
Where SGLang Pulls Ahead and Where vLLM Still Feels Safer
The easiest way to make this comparison useful is to stop treating both projects as interchangeable. They overlap a lot, but they do not feel identical once you look at the workload you are actually trying to run.
SGLang tends to pull ahead when your serving layer is part of the product logic rather than just a throughput utility. Its current positioning makes that clear: structured outputs, multimodal support, scheduler behavior, and more specialized runtime control are not side notes. They are central to why many teams evaluate it in the first place.
That makes SGLang especially compelling when:
- structured outputs need to be reliable and operationally important
- multimodal serving is part of the near-term roadmap, not a vague future possibility
- your team wants more explicit control over runtime behavior
- you are choosing a serving framework partly for systems-level differentiation
vLLM still feels safer when the real goal is to get a strong production baseline online with minimal friction. It remains the more familiar default in many teams because it is widely recognized, strongly associated with high-throughput serving, and easier to justify internally as the mainstream starting point.
That usually makes vLLM the better fit when:
- you want the broad default deployment path first
- your main priority is efficient text-model serving
- the team values adoption, documentation surface, and ecosystem familiarity
- you would rather begin with the standard baseline and specialize later if needed
So the better framing is not SGLang wins versus vLLM wins. It is whether your deployment needs a broad default engine or a more opinionated serving stack.
Why RunC.ai Is a Practical Option for Either SGLang or vLLM
Once you know whether SGLang or vLLM is the better fit, the next decision is infrastructure: where can you run that serving stack in a way that stays repeatable, cost-aware, and easy to scale?
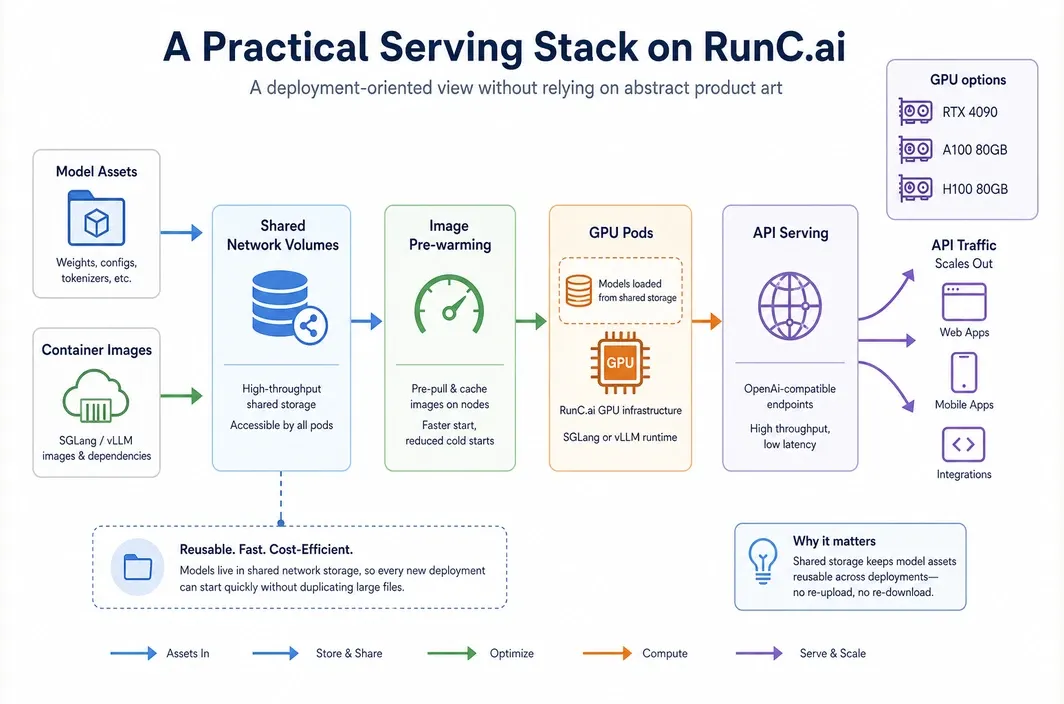
In that context, RunC.ai is relevant as the deployment layer rather than the comparison subject. For teams deploying either framework, the practical advantages are:
GPU Podsfor persistent, dedicated GPU environments- pricing signals from
RTX 4090 at $0.42/hr,A100 80GB at $1.60/hr, andH100 80GB at $2.56/hr Shared Network Volumesfor reusable model assets and weights across PodsImage Pre-warmingto reduce startup friction for custom container images
Those capabilities matter because inference systems are rarely deployed once and left alone. Teams usually need reusable environments, shared model storage, and a clean path from lower-cost testing to higher-memory production serving.
How to Choose Between SGLang and vLLM
The easiest way to choose is to walk through the decision in the same order your deployment will probably unfold.
- Start with workload shape. If you mainly need a familiar text-serving baseline, vLLM is usually the easier first move. If structured outputs, multimodal support, or runtime behavior already shape the architecture, SGLang deserves more serious attention from day one.
- Then check team tolerance for tuning. vLLM is usually easier to justify when you want low-friction adoption. SGLang makes more sense when your team is willing to trade some simplicity for more explicit serving control.
- Finally, separate framework choice from infrastructure choice. The serving framework answers how you want to run the model. The cloud decision answers how easily you can keep that setup repeatable, persistent, and cost-aware.
For many teams, the practical choice ends up being straightforward: start with vLLM when you want the safest default, move toward SGLang when your workload clearly benefits from its runtime priorities, and solve the deployment environment alongside that choice instead of leaving it for later.
FAQ
What is the main difference between SGLang and vLLM?
The main difference is not that one serves LLMs and the other does not. Both do. The difference is in emphasis: vLLM is usually treated as the mainstream high-throughput default, while SGLang places more visible emphasis on advanced runtime behavior, structured outputs, and multimodal-oriented serving capabilities.
Is SGLang faster than vLLM?
Sometimes, depending on workload and configuration, but that is not a safe universal claim to publish without workload-specific benchmarking. The better framing is that SGLang emphasizes aggressive serving optimizations, while vLLM remains strongly optimized and widely adopted for high-throughput inference.
Is vLLM easier to deploy than SGLang?
For many teams, yes. vLLM explicitly emphasizes ease of use in its design philosophy, and it is often treated as the lower-friction default starting point for production serving.
Does SGLang support OpenAI-compatible APIs?
Yes. SGLang's official documentation includes OpenAI-compatible APIs, including completions and related serving flows.
Which cloud infrastructure is better for SGLang or vLLM?
The best infrastructure is the one that gives you the right GPU class, persistent storage, and repeatable deployment model for your workload. Dedicated GPU environments like RunC.ai GPU Pods are a good fit when you want custom control over your serving stack.
Conclusion
The SGLang vs vLLM decision is not really about picking a winner in a vacuum. It is about choosing the serving framework that best matches your workload, team preferences, and deployment style.
vLLM is often the better default starting point when you want broad adoption, familiarity, and a low-friction serving path. SGLang is often the more interesting choice when your requirements tilt toward runtime sophistication, structured serving, or multimodal-heavy deployment. Once you know which framework fits your serving model, a dedicated GPU platform like RunC.ai gives you a practical way to deploy either one on infrastructure that can scale from RTX 4090 to A100 or H100 as your workloads grow.

Member discussion: