
What is Satori-7B-Round2?
Satori-7B-Round2 is a 7B-parameter large language model developed by researchers from institutions such as MIT and Harvard University, focusing on enhancing reasoning capabilities. Based on Qwen-2.5-Math-7B, Satori achieves advanced reasoning performance through small-scale format fine-tuning and large-scale reinforcement learning.
The model introduces the Action-Thinking Chain (COAT) mechanism, guiding the model to perform reasoning through special meta-action tags. Satori demonstrates outstanding performance in mathematical reasoning and cross-domain tasks, showcasing excellent generalization capabilities.
The core ability of Satori-7B-Round2
● Self-regressive search capability: Satori can perform self-regressive searches through self-reflection and exploration of new strategies, enabling it to complete complex reasoning tasks without external guidance.
● Mathematical reasoning: Satori achieved the best results in mathematical reasoning benchmark tests, demonstrating exceptional reasoning capabilities.
● Cross-domain tasks: In addition to mathematics, Satori also performed exceptionally well in cross-domain tasks such as logical reasoning, code reasoning, common sense reasoning, and table reasoning, demonstrating strong generalization capabilities.
● Self-reflection and error correction: Satori can self-reflect and self-correct during the reasoning process, improving the accuracy of its reasoning.
● Reinforcement learning optimization: Utilizing the Action-Thinking Chain (COAT) mechanism and a two-stage training framework, including small-scale format tuning and large-scale self-optimization, Satori primarily relies on reinforcement learning (RL) to achieve advanced reasoning performance.
● The technical principles of Satori-7B-Round2 - COAT

○ Continue Reasoning (<|continue|>): encourages the LLM to build upon its current reasoning trajectory by generating the next intermediate step.
○ Reflect (<|reflect|>): prompts the model to pause and verify the correctness of prior reasoning steps.
○ Explore Alternative Solution (<|explore|>): signals the model to identify critical flaws in its reasoning and explore a new solution.
● The two-phases training frame
○ Small-scale format optimization phase: Fine-tune the model on a small dataset of inference trajectory examples to familiarize it with the COAT inference format.
○ Large-scale self-optimization phase: Optimize model performance through reinforcement learning (RL) using restart and exploration (RAE) techniques to enhance the model's autoregressive search capabilities.
Mathmatical reasoning benchmark of Satori-7B-Round2
Small-scale format optimization phase: Fine-tune the model on a small dataset of inference trajectory examples to familiarize it with the COAT inference format.
Large-scale self-optimization phase: Optimize model performance through reinforcement learning (RL) using restart and exploration (RAE) techniques to enhance the model's autoregressive search capabilities.

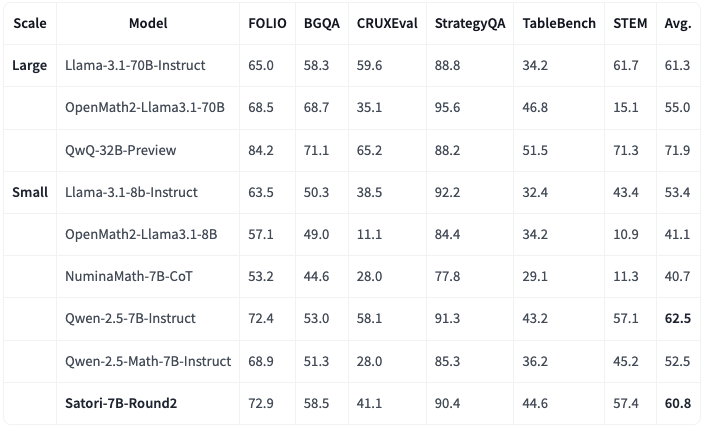
General domain reasoning benchmark of Satori-7B-Round2
Satori-7B-Round2, trained only on the mathematics dataset , shows strong transfer capabilities across multiple out-of-domain reasoning benchmarks and significantly surpasses Qwen-2.5-Math-7B-Instruct.
Despite not being trained on other domains, Satori-7B-Round2 performs as well as or better than other small general-purpose instruction models and is comparable to larger models such as Llama-3.1-70B-Instruct.
What is Satori-7B-Round2-WebUI?
Satori-7B-Round2-WebUI is an open source project that provides a friendly WebUI based on the Satori-7B-Round2 inference model and Gradio API, which can facilitate rapid depolyment and experience of the model's inference capabilities.
Deployment of Satori-7B-Round2-WebUI on RunC.AI
1. First of all, sign in/up RunC.AI | Run clever cloud computing for AI (You can get $5 free credits by finishing the survey on our website, about 12h of 4090 usage time)
Secondly, enter the console. Go to "Instance" and click "Deploy" to start creating the image. Scroll down to “Image”, and choose “Container Image”. We will select “PyTorch” for this tutorial. You can change the name of your instance below.
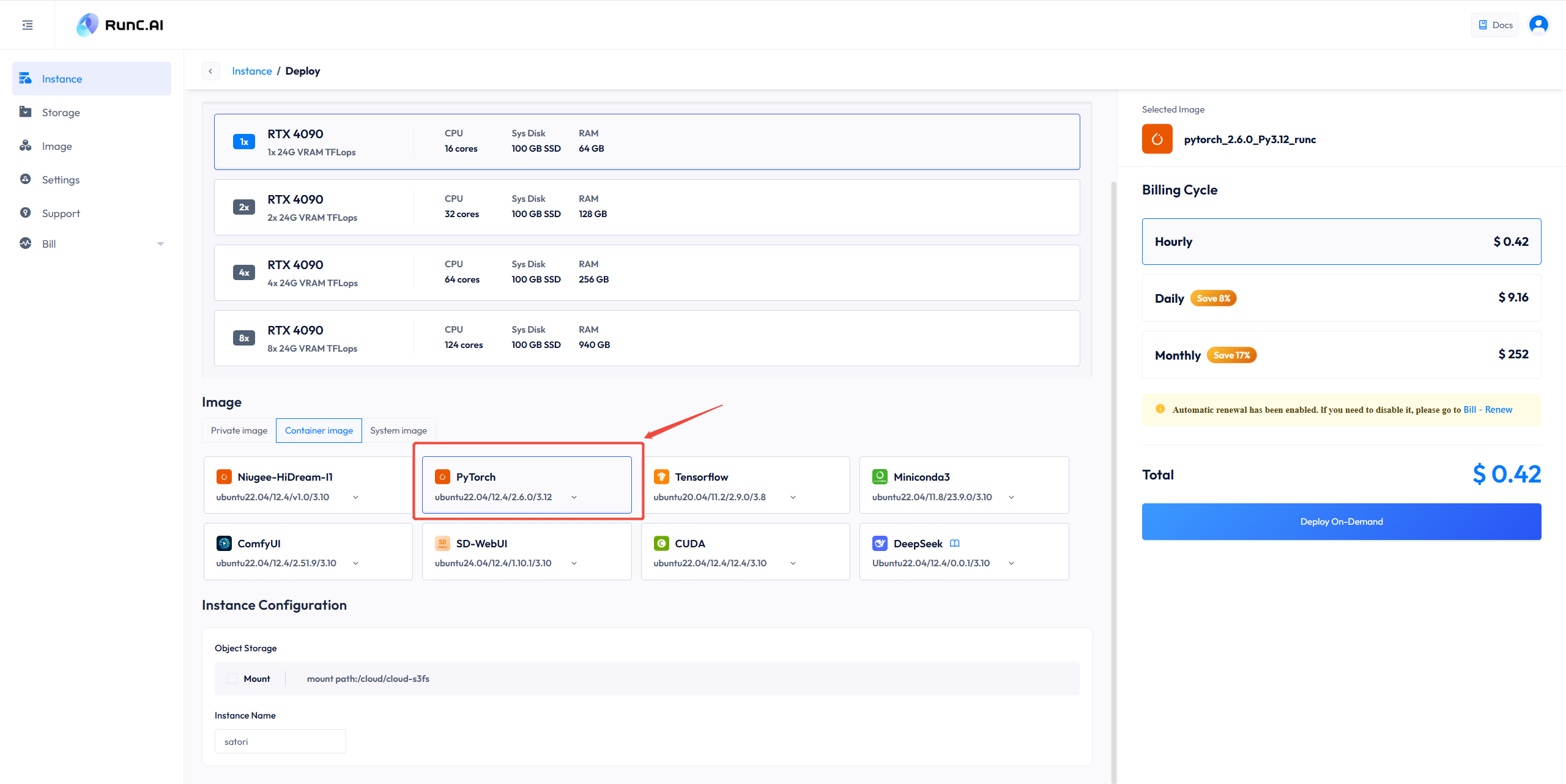
Click 'Deploy on-Demand'. and wait for a few seconds to initialize the instance.
You will see the panel like this, when the status turns into 'running', you can continue the next xtep. if the status remains 'initialize' for five minutes, you can send a ticket to us.

2. Click 'Jupyter Lab' and enter the Terminal.

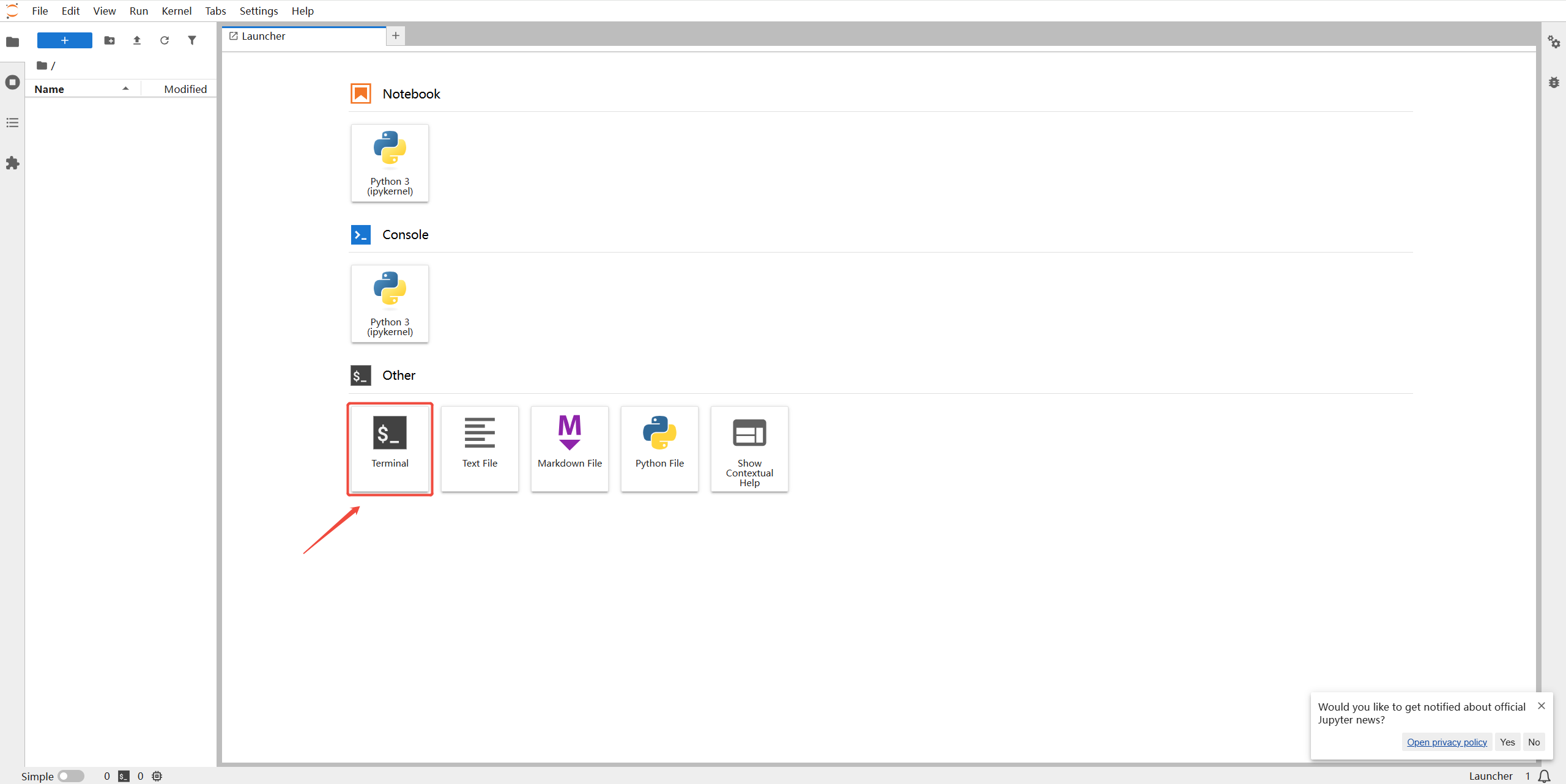
Type in the following commands:
cd AI
python -m venv myenv
source myenv/bin/activate
pip install torch vllm gradio tqdm
python gradio_app.py --share --host 0.0.0.0 --port 7860

After a few minutes downloading, you will see a link occur at the bottom. Click it, and you can instantly see the operating interface.
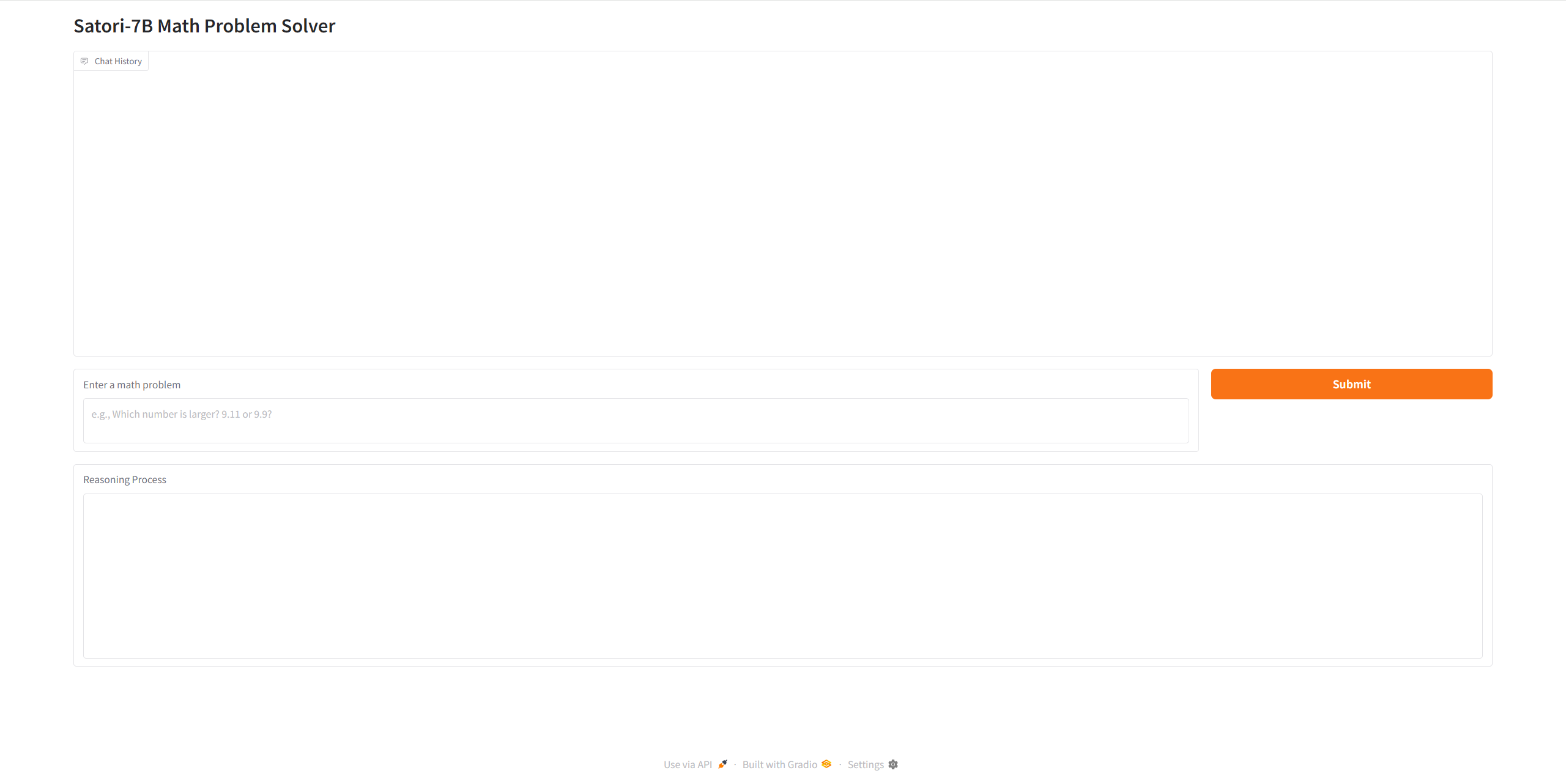
Let's enter a mathmetical problem to see how it perform. Enter a math problem, submit, the answer will show in the box on the top, and the reasoning process will show in the last box. Here I enter a trigonometric function problem as an example, and as you can see, the model is really powerful — short reasoning time, precise answer, and simple to use.
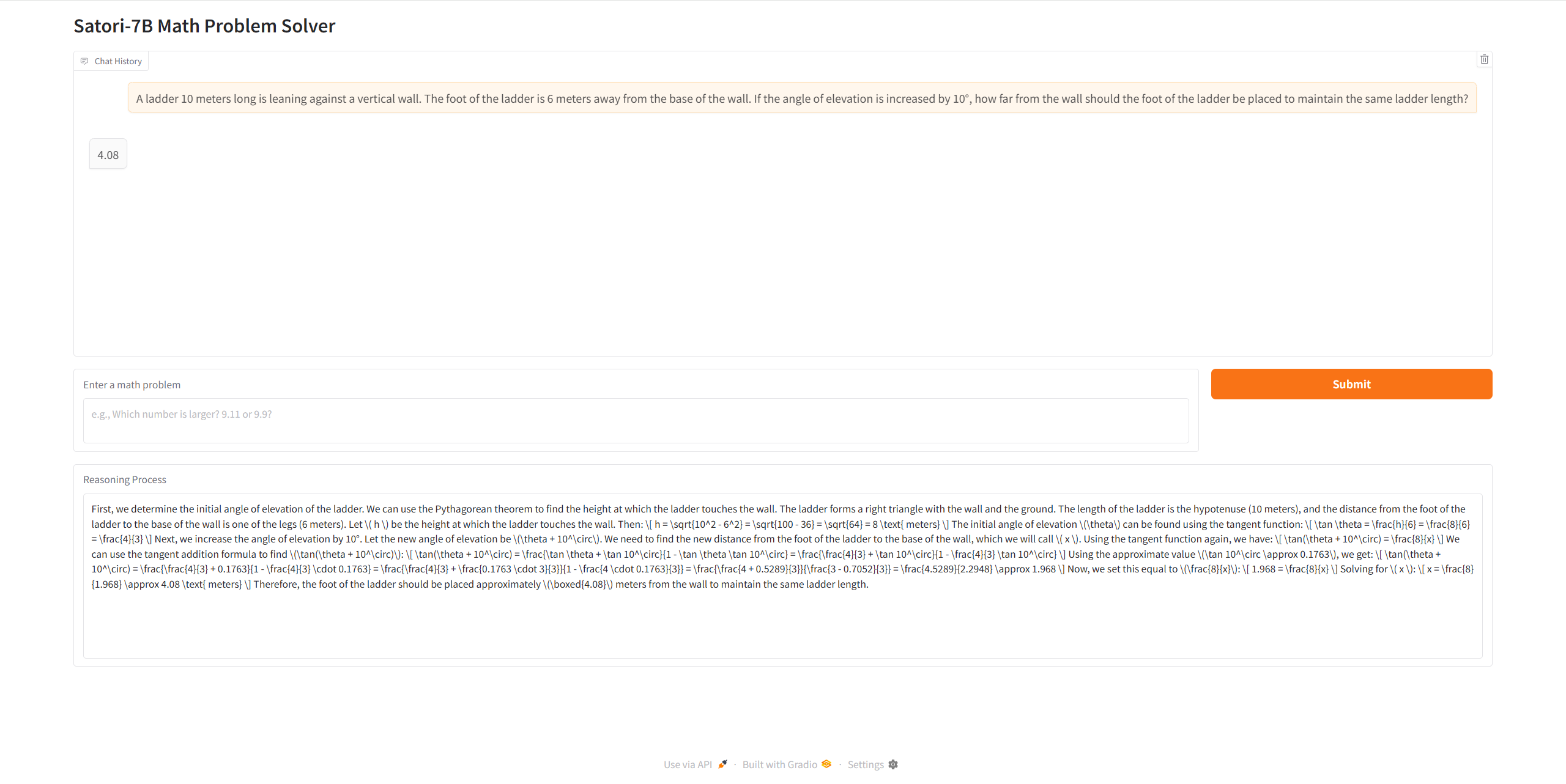
I hope this tutorial was helpful. Feel free to leave a comment if you have any questions!
Stay tuned — we’ll continue sharing more in the future!
About RunC.AI
Rent smart, run fast. RunC.AI allows users to gain access to a wide selection of scalable, high-performance GPU instances and clusters at competitive prices compared to major cloud providers like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure.
