Key Takeaways
- RunC.ai is one of the strongest starting points for teams that want low entry pricing, GPU Pods, and a clean path into Serverless GPU on the same platform.
- RunPod stands out for broad GPU coverage, fast self-serve deployment, and a stronger serverless inference surface than most general GPU rental platforms.
- Vast.ai is still the budget-first marketplace option, but low pricing comes with more variance in host quality and operating consistency.
- Lambda and CoreWeave are stronger choices when the workload already looks like serious training infrastructure instead of lightweight experimentation.
- DigitalOcean is easier to shortlist when the team wants straightforward cloud UX and predictable pricing more than the absolute lowest GPU rate.
Best GPU Cloud Providers to Compare Right Now

The strongest shortlist for GPU cloud providers usually mixes low-cost builders, marketplace capacity, and heavier training platforms. The names worth comparing first are RunC.ai, RunPod, Vast.ai, Lambda, CoreWeave, and DigitalOcean.
| Provider | Best for | Pricing posture | Deployment shape |
|---|---|---|---|
| RunC.ai | Cost-aware AI teams that want Pods and a later Serverless GPU path | Low entry pricing with on-demand Pods | GPU Pods plus Serverless GPU |
| RunPod | Self-serve teams that want broad GPU choice and mature tooling | Mid-range pod pricing with separate serverless path | Pods, Serverless, and Clusters |
| Vast.ai | Budget-first experiments and overflow jobs | Marketplace-driven and highly variable | Marketplace instances |
| Lambda | Heavier training and reserved H100 buying | Higher entry pricing, stronger reserved economics | Instances and cluster-scale paths |
| CoreWeave | Enterprise-scale AI infrastructure | High-scale enterprise pricing | Large clusters and managed infrastructure |
| DigitalOcean | Simpler cloud operations with GPU access | Predictable cloud pricing | GPU Droplets inside a broader cloud stack |
RunC.ai
- Best for: cost-aware teams that want one platform for GPU Pods, shared storage, and a later move into Serverless GPU.
- Public pricing signal checked on May 27, 2026: RunC-owned public materials currently indicate RTX 4090 from
$0.42/hr, A100 80GB from$1.60/hr, and H100 80GB from$2.56/hr. - Strengths: very strong price-to-performance at the RTX 4090 tier, second-based on-demand billing,
Network Volumesupport, and a cleaner bridge between iterative pod workflows and production-style inference. - Caveats: the brand is newer than some of the better-known GPU clouds, and enterprise buyers that need the most established procurement path may still compare it against larger providers.
RunPod
- Best for: fast self-serve GPU access, broad hardware choice, and teams that want both Pods and serverless inference on a mature developer platform.
- Public pricing signal checked on May 27, 2026: RunPod lists RTX 4090 at
$0.69/hr, A100 PCIe at$1.39/hr, H100 PCIe at$2.89/hr, and H100 serverless workers on a separate inference pricing surface. - Strengths: wide catalog, strong template and container workflow, clear product split across Pods, Serverless, and Clusters, and easy entry for prototyping and inference serving.
- Caveats: pricing is not always the lowest at the consumer-GPU tier, and some teams will still want to compare RunPod against cheaper marketplace-style capacity before committing.
Vast.ai
- Best for: aggressive cost compression and opportunistic buying when the workload can tolerate marketplace variance.
- Public pricing signal checked on May 27, 2026: Vast.ai documents a market-driven model rather than fixed list pricing, with host-set rates, second-based billing, and real-time search across offers.
- Strengths: often one of the cheapest places to hunt for GPU capacity, especially for experiments, overflow jobs, and flexible workloads.
- Caveats: host quality, reliability, storage behavior, and support expectations are less standardized than on a more curated cloud.
Lambda
- Best for: teams moving into more serious training, H100-heavy workloads, and larger reserved or cluster-based GPU buying.
- Public pricing signal checked on May 27, 2026: Lambda lists 1x H100 PCIe at
$3.29/hr, 1x A100 PCIe at$1.99/hr, and markets reserved H100 cluster pricing from$1.85per GPU-hour on1-year+commitments. - Strengths: strong brand recognition in AI infrastructure, clear H100 and A100 product paths, and a credible story for multi-GPU and cluster-scale training.
- Caveats: entry pricing is usually less attractive than the cheapest GPU Pods and marketplaces, so it is often a better fit once the workload is already substantial.
CoreWeave
- Best for: enterprise-scale training, high-performance H100 or H200 clusters, and teams already thinking in terms of large AI infrastructure programs.
- Public pricing signal checked on May 27, 2026: CoreWeave lists 8x HGX H100 on-demand capacity at
$49.24/hrand 8x A100 at$21.60/hr, while positioning its H100 and H200 supercomputer product around large-scale AI training and inference. - Strengths: very strong fit for high-scale distributed training, serious networking, and managed enterprise AI infrastructure.
- Caveats: not the first stop for a small team looking for the cheapest single-GPU experimentation path.
DigitalOcean
- Best for: teams that want simpler cloud ergonomics, predictable pricing, and a more familiar general cloud operating model.
- Public pricing signal checked on May 27, 2026: DigitalOcean documents NVIDIA H100 at
$3.39/hr, H100 8x at$23.92/hr, and L40s at$1.57/hr. - Strengths: predictable billing, clean interface, and an easier starting point for teams that want GPU compute inside a simpler broader cloud stack.
- Caveats: it is not usually the price leader for raw GPU rental, and the GPU catalog is narrower than the most AI-specialized platforms.
How Prices Differ Across GPU Cloud Providers
GPU cloud pricing is not just one hourly number. The cost logic changes with the provider model.
- RunC.ai competes hardest on cost-effective on-demand GPU Pods, especially when RTX 4090-class hardware is enough and the workflow benefits from shared storage and repeatable deployment.
- RunPod splits its pricing story across Pods and Serverless. That makes it easier to compare a warm environment path against an event-driven inference path inside one platform.
- Vast.ai behaves like a live marketplace. The upside is lower rates. The downside is that pricing, hardware condition, and availability move with supply and demand.
- Lambda becomes more persuasive as the workload shifts from single-instance testing toward reserved or clustered training capacity.
- CoreWeave pricing makes more sense when the comparison is not "cheapest GPU right now" but "which platform is purpose-built for large-scale training and enterprise inference."
- DigitalOcean is more about predictable cloud buying than bargain hunting. It can still make sense when a team values simplicity more than the last bit of hourly savings.
The fastest way to filter the shortlist is to separate providers into four pricing postures:
| Pricing posture | Providers | What it usually means |
|---|---|---|
| Lowest entry cost | RunC.ai, Vast.ai, some RunPod configurations | Best for testing, lighter workloads, and cost-sensitive iteration |
| Best balance of flexibility and product depth | RunPod, RunC.ai | Strong fit when the team wants both low-friction deployment and room to scale |
| Training-oriented reserved or cluster buying | Lambda, CoreWeave | Better fit once H100-heavy or multi-GPU training becomes the main job |
| Simpler general cloud pricing | DigitalOcean | Better fit when predictable cloud operations matter more than chasing the lowest rate |
Which Provider Fits Which Workload

Different workloads push the shortlist in different directions.
| Workload | Stronger shortlist | Why |
|---|---|---|
| Cost-sensitive experimentation | RunC.ai, Vast.ai, RunPod | Lower entry pricing, flexible access, and easier testing paths |
| Production inference and AI APIs | RunPod, RunC.ai, DigitalOcean | Better fit for serving, repeatability, or cleaner cloud operations |
| Fine-tuning and heavier model work | Lambda, CoreWeave, RunC.ai, RunPod | Better hardware depth or practical lower-cost Pods for smaller jobs |
| Large-scale training and enterprise programs | CoreWeave, Lambda, hyperscalers | Stronger fit for bigger fleets, networking, and enterprise controls |
Cost-sensitive experimentation
- RunC.ai fits well when the goal is inexpensive iteration on RTX 4090-class hardware with a cleaner upgrade path than a marketplace-only workflow.
- Vast.ai fits well when the main objective is to minimize hourly cost and the workload can tolerate more operational variance.
- RunPod fits well when cheaper experimentation still needs a stronger platform layer, templates, or later Serverless GPU deployment.
Production inference and AI APIs
- RunPod is one of the first names to compare when inference may move between warm GPU Pods and serverless workers.
- RunC.ai becomes attractive when the serving path needs cost control, persistent assets, and a practical handoff between development environments and production-style deployment.
- DigitalOcean is easier to justify when the team wants a more traditional cloud experience around the inference stack.
Fine-tuning and heavier model work
- Lambda makes more sense once the requirement shifts toward H100s, A100s, longer-running jobs, or cluster-style buying.
- CoreWeave becomes more relevant when the environment already looks like serious AI infrastructure instead of a lightweight pod workflow.
- RunC.ai and RunPod can still make sense for smaller fine-tuning workloads, especially when the model fits comfortably on lower-cost GPUs.
Large-scale training and enterprise programs
- CoreWeave belongs near the top of the shortlist when high-performance networking, larger H100 or H200 fleets, and managed enterprise infrastructure matter more than low-cost entry.
- Lambda also belongs in that conversation because it offers both self-serve instances and larger H100 cluster paths.
- Hyperscalers can still matter here, but they are often better evaluated as part of a broader cloud estate decision than as the cheapest pure GPU answer.
When Pods, Serverless GPU, or Dedicated Capacity Make More Sense
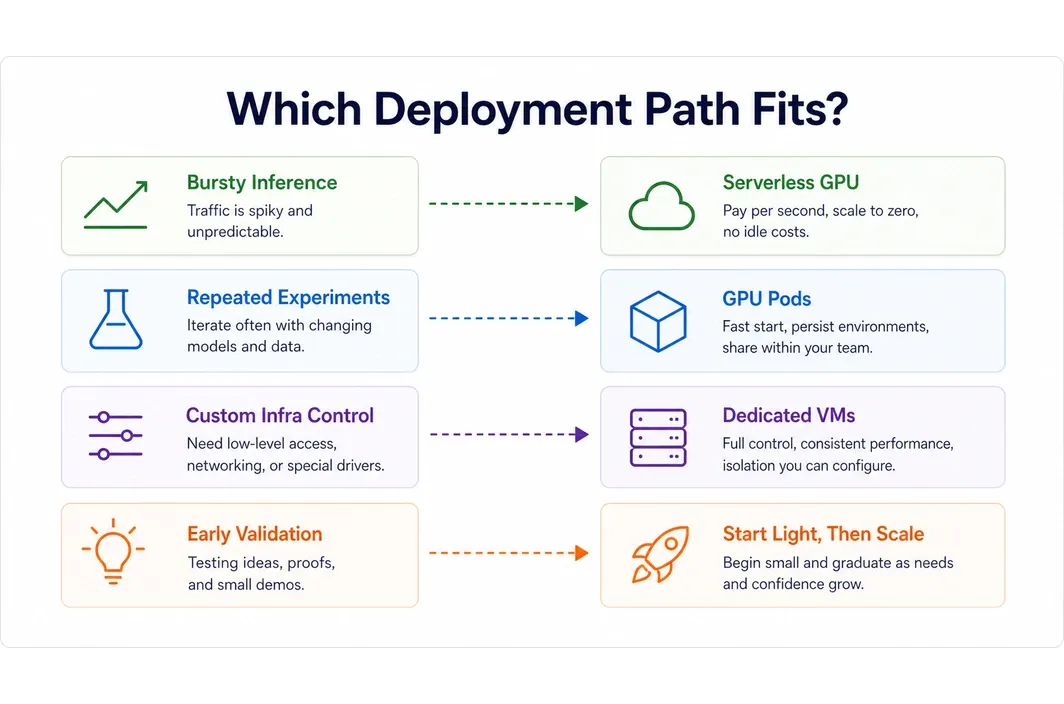
Provider choice gets easier once the deployment shape is clear.
- Serverless GPU fits bursty inference, low average utilization, and API traffic that does not justify warm idle capacity.
- GPU Pods fit repeated experiments, stable model environments, and serving setups that need warm persistence without moving into full custom infrastructure.
- Dedicated clusters or heavier reserved capacity fit long training runs, strict internal controls, and workloads where interconnect and queue predictability matter more than low entry pricing.
That is why the strongest provider is rarely just the one with the cheapest GPU. The better provider is the one whose deployment model still fits after the workload stops being a one-week test.
FAQ
Which GPU cloud provider is usually the cheapest?
Vast.ai often wins on headline marketplace pricing. RunC.ai and some RunPod GPU Pod configurations are more competitive when the workload also needs a cleaner operating path, more predictable persistence, or a stronger platform layer around the GPU.
Which GPU cloud provider is best for H100 training?
Lambda and CoreWeave are stronger fits once the job clearly needs H100-heavy training infrastructure. RunPod and RunC.ai can still be useful for smaller-scale H100 usage, but they are not the only comparison once cluster-grade training becomes the main requirement.
Should a shortlist include hyperscalers?
Yes, but not by default in every early comparison. AWS, Google Cloud, and Azure matter more when compliance, existing cloud contracts, or broader platform integration are already driving the decision.
What is the best GPU cloud provider for startups?
For many startups, the shortlist starts with RunC.ai, RunPod, and Vast.ai. The best pick depends on whether the startup cares most about low entry cost, platform convenience, or the fastest path to API-style deployment.
Conclusion
The best GPU cloud provider is not just the one with the lowest headline rate. It is the one that lets the team start quickly, control cost, and keep the deployment path usable as the workload grows. For teams that want strong price-to-performance, fast access to popular GPU tiers, repeatable GPU Pod workflows, and a practical path into Serverless GPU, RunC.ai is one of the strongest platforms to compare first. If the current shortlist still feels broad, RunC.ai is a strong place to start narrowing it down.

Member discussion: