
Key Takeaways
- Cheap LLM APIs are not defined by input token price alone. Output rates, cache pricing, batch discounts, and tool-call behavior often matter more.
- In current official pricing, the low-cost floor is set by models such as
Gemini 2.5 Flash-LiteandDeepSeek-V4-Flash, while premium general-purpose models still cost much more per token. - A model that looks cheap on a pricing page can become expensive if it generates long answers, replays large prompts, or uses reasoning-heavy workflows.
- APIs are usually still the best deal for light, bursty, or early-stage products because they remove infrastructure work and idle GPU cost.
- Once traffic becomes steady and predictable, teams should stop comparing token prices in isolation and start comparing API spend against dedicated GPU inference on RunC.ai.
Introduction
People searching for cheap llms apis usually want a simple answer: which provider has the lowest price right now. That is a useful place to start, but it does not control a real production bill by itself. A cheap rate card can still turn into an expensive product if the model produces too many output tokens, reprocesses the same context on every call, or sits inside an agent loop that keeps paying for its own history.
The better question is not only which API looks cheapest on paper. It is which cost model fits your workload. A support bot, a document extraction pipeline, and a coding agent can all hit the same API and end up with completely different economics.
As of May 9, 2026, the official pricing pages already show how wide the spread has become. OpenAI lists GPT-5.4 mini at $0.75 / 1M input tokens and $4.50 / 1M output tokens. Anthropic lists Claude Haiku 4.5 at $1 / MTok input and $5 / MTok output. Google's Gemini API lists Gemini 2.5 Flash-Lite at $0.10 / 1M input and $0.40 / 1M output. DeepSeek lists DeepSeek-V4-Flash at $0.14 / 1M cache-miss input and $0.28 / 1M output. Those numbers matter, but they are only the first layer of the bill, and they should be treated as a dated snapshot rather than a permanent ranking.
Headline Token Prices Are Only the First Layer of "Cheap"
The first trap in cheap LLM API buying is treating the input token rate as the full story. In practice, most providers charge separately for:
- input tokens
- output tokens
- cached or repeated context
- batch or deferred processing
- extra tools or grounded search flows
That means two models can look close on input price and still diverge sharply in real cost. Output tokens are the clearest example. If your application generates long answers, the output column can dominate the bill much faster than people expect.
There is also a second trap: some teams compare only flagship models when the actual workload could live on a much cheaper tier. If your application mostly does extraction, routing, summarization, light chat, or structured output, you may not need a premium model on every request. For many products, the biggest cost win comes from matching the workload to the right tier rather than from chasing a single provider.
A Current Official Pricing Snapshot
The table below is not a "best provider" ranking. It is a snapshot of where official pricing sits today for a few widely discussed API options.
| Provider / model | Official input price | Official output price | Pricing note |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 / 1M |
$0.40 / 1M |
Google's smallest cost-focused Gemini API model |
| DeepSeek-V4-Flash | $0.14 / 1M cache-miss |
$0.28 / 1M |
1M context on current official pricing page |
| Gemini 2.5 Flash | $0.30 / 1M |
$2.50 / 1M |
Hybrid reasoning model with a 1M token context window |
| GPT-5.4 mini | $0.75 / 1M |
$4.50 / 1M |
OpenAI mini tier with lower-cost cached input pricing |
| Claude Haiku 4.5 | $1 / MTok |
$5 / MTok |
Anthropic budget Claude tier |
| GPT-5.4 | $2.50 / 1M |
$15.00 / 1M |
Premium general-purpose OpenAI tier |
| Claude Sonnet 4.6 | $3 / MTok |
$15 / MTok |
Mid-to-premium Claude tier |
This is where a lot of cheap llms apis advice goes wrong. People see that Gemini 2.5 Flash-Lite is cheaper than GPT-5.4 mini on a rate-card basis and stop there. The next question is the one that matters: what does a realistic workload cost once inputs, outputs, cache behavior, and request shape are included?
For example, imagine a workload that consumes 100M input tokens and returns 20M output tokens in a month:
| Model | Example monthly math | Estimated cost |
|---|---|---|
| Gemini 2.5 Flash-Lite | 100 x $0.10 + 20 x $0.40 |
$18 |
| DeepSeek-V4-Flash | 100 x $0.14 + 20 x $0.28 |
$19.6 |
| GPT-5.4 mini | 100 x $0.75 + 20 x $4.50 |
$165 |
| Claude Haiku 4.5 | 100 x $1 + 20 x $5 |
$200 |
Those numbers do not mean one model is universally better. They show how quickly the cost gap widens when the same traffic pattern is applied across different tiers.
If you publish or rely on this comparison later, re-check the provider pricing pages first. The cost logic in the article should hold up longer than any single rate card.

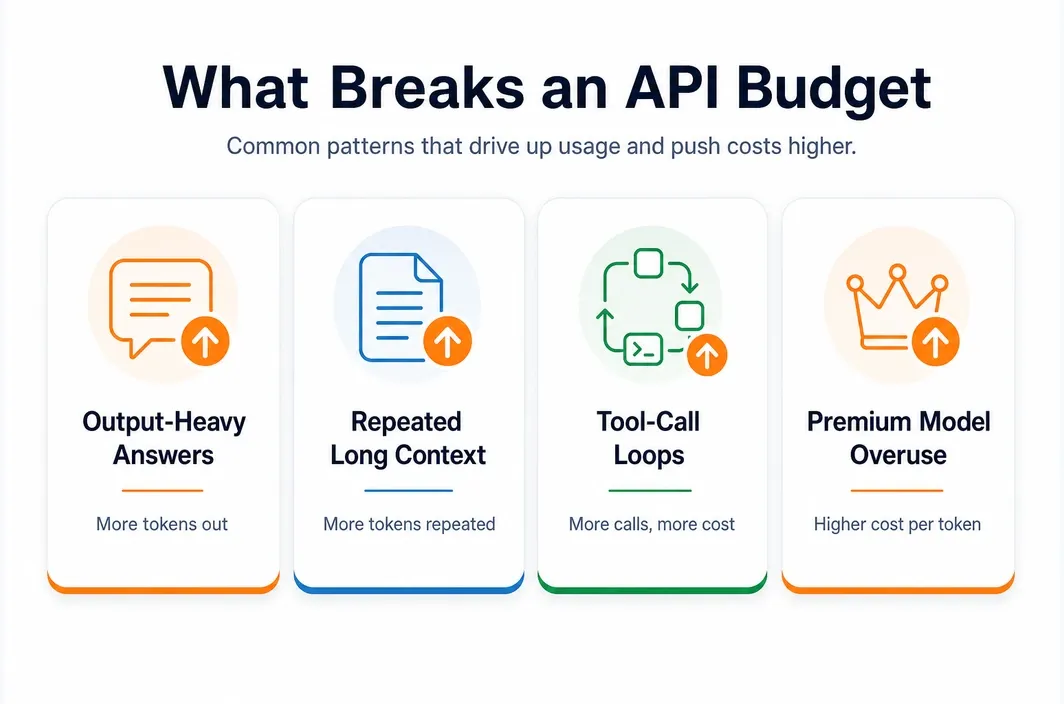
Four Cost Multipliers That Quietly Break a Budget
If you want a cheaper LLM API bill, these are usually the four places to look before switching vendors.
| Cost multiplier | Why it matters | What to do |
|---|---|---|
| Output-heavy answers | Output tokens often cost much more than input tokens | shorten defaults, cap output, and avoid verbose prompts |
| Repeated long context | Large system prompts, docs, and chat history get repaid over and over | use caching where supported and trim context aggressively |
| Tool-call loops | Agents keep replaying message history across multiple calls | separate routing, tool use, and final generation instead of using one expensive loop |
| Premium model overuse | Teams send every request to the same high-cost model | route easy tasks to cheaper models and reserve premium models for hard requests |
Output cost is the most common blind spot. On the current official pages checked for this article, the output price is several times higher than the input price for every provider in the snapshot above. That means a chatty assistant can quietly cost more than a smarter but shorter-answering model.
Caching is the next big lever. OpenAI lists much lower cached-input pricing than standard input pricing, Anthropic shows separate cache-hit pricing, and Google lists context caching for Gemini. If your product keeps reusing the same policy prompt, retrieval context, or long instructions, caching can change the economics more than switching from one model family to another.
Batch pricing matters too. OpenAI's pricing page says the Batch API saves 50% on inputs and outputs. Google's Gemini API also publishes lower batch and flex rates for Gemini 2.5 Flash. That will not help a real-time chat endpoint, but it can matter a lot for overnight summarization, backfills, evaluation jobs, or queued document work.
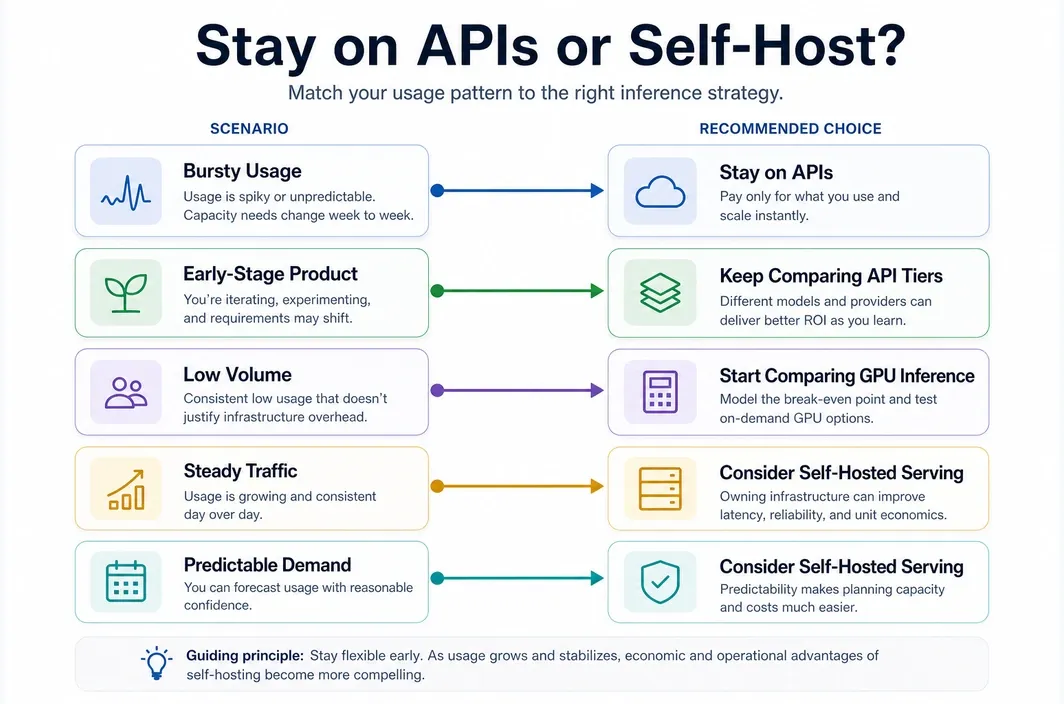
When APIs Are Still the Cheapest Option
Cheap LLM APIs stay genuinely cheap when the workload is light, bursty, or uncertain.
That usually includes:
- early-stage products that are still finding demand
- internal tools with inconsistent usage
- prototypes where engineering speed matters more than infrastructure efficiency
- workloads that need several model providers for testing before standardization
In those cases, the API bill is paying for more than tokens. It is paying for no GPU procurement, no model serving stack, no autoscaling layer, and no idle infrastructure sitting around waiting for traffic.
That is why a team should not rush into self-hosting just because a model looks expensive at first glance. If monthly usage is still low or uneven, the operational overhead of running your own inference stack can erase the savings. A cheap API is often the right answer because it lets the team avoid owning a whole serving system too early.
When It Stops Making Sense To Keep Chasing Cheaper APIs
There is a point where the real optimization problem changes. Once volume becomes steady, predictable, and large enough, switching from one cheap API to another may no longer be the main win. The bigger win may come from changing the delivery model entirely.
That is where RunC.ai becomes relevant. Once traffic is steady enough that the monthly API bill starts to look like a repeatable infrastructure cost, the better question is no longer which provider is a little cheaper per token. It is whether that recurring spend would be better translated into dedicated inference on pay-as-you-go GPU Pods. The practical question becomes:
- is the workload stable enough to keep a GPU busy
- can an open or self-served model meet the product requirement
- would predictable hourly infrastructure cost beat variable per-token API spend
RunC.ai fits that transition well when a team wants to test a different cost model without jumping straight into heavyweight infrastructure. What matters here is practical control: pay-as-you-go hourly billing, known pricing signals such as RTX 4090 around $0.42/hr in RunC materials, and operational pieces such as Shared Network Volumes when the inference stack needs shared weights, caches, or datasets. In other words, it gives teams a cleaner way to compare monthly token spend against hourly inference economics instead of endlessly hunting for the next slightly cheaper API tier.
That does not mean every team should self-host. It means cheap LLM APIs are often the best first answer, while a cost-effective GPU cloud becomes the stronger second answer once traffic matures.
FAQ
What is the cheapest LLM API right now?
There is no stable single winner that stays true across every workload. As of May 9, 2026, official pricing pages show very low-cost options such as Gemini 2.5 Flash-Lite and DeepSeek-V4-Flash, but the cheapest useful choice still depends on output length, context reuse, workflow design, and whether those prices are still current when you read them.
Why can a cheap LLM API still feel expensive in production?
The headline token price usually ignores output-heavy answers, repeated context, agent loops, and premium-model overuse. In production, those patterns often matter more than the input rate on the pricing page.
When should I stop using APIs and look at self-hosting?
Start asking that question when traffic becomes steady enough that you are paying a large bill every month for a predictable workload. That is the moment to compare recurring API spend against dedicated inference on a GPU cloud such as RunC.ai.
Are batch discounts worth using?
Yes, if the workload is asynchronous. OpenAI's official pricing page says Batch API pricing is 50% lower on inputs and outputs, and Google publishes lower batch pricing for Gemini Flash. For queued jobs, that can be one of the easiest cost reductions available.
Conclusion
Cheap LLM APIs are easy to misunderstand because the first number everyone sees is the input token price. The real cost model is wider than that. Output rates, cache behavior, batch eligibility, and workload shape all decide whether an API stays cheap after launch.
If your usage is still bursty, experimental, or small, a low-cost API tier is usually the cleanest answer. If your traffic becomes stable enough to justify a serving stack of your own, stop treating cheap llms apis as only a provider-ranking problem. At that stage, the more useful move is to compare monthly API spend against hourly GPU inference economics on RunC.ai and see whether the cheaper path is no longer a different API, but a different delivery model.

Member discussion: