
Key Takeaways
- The best serverless GPU cloud depends on what you need most: low-friction deployment, code-first control, production inference features, or a cleaner path into more persistent GPU capacity.
- Start with real providers, concrete tradeoffs, and a clear match to workload type.
- RunPod, Modal, Replicate, Baseten, Beam, and fal all deserve attention for different reasons, but they solve different operational problems.
- RunC belongs on the shortlist for teams that care about cost-sensitive AI deployment and may want to move from event-driven serving into GPU Pods without changing platforms.
- Serverless GPU is strongest for bursty inference and weakest when cold starts, repeated model loading, or always-warm environments matter more than zero-idle billing.
Introduction

Serverless GPU platforms are easiest to justify when the workload is bursty, the team wants fast deployment, and zero-idle billing actually saves money. RunPod, Modal, Replicate, Baseten, Beam, and fal all fit that category, but they differ quickly once runtime control, autoscaling behavior, observability, and deployment style matter.
Some teams want the fastest route from model code to an endpoint. Others need stronger production controls, cleaner container handling, or a smoother move beyond pure scale-to-zero infrastructure.
RunC is relevant in that mix because Serverless GPU (Preview) sits alongside a more persistent Pod path on the same platform. That makes it easier to compare burst-mode serving with a warmer deployment model before the workload outgrows strict serverless assumptions.
What Actually Matters When Comparing Serverless GPU Clouds
Use the same comparison criteria across every provider.
The differences usually become clearer in these five areas:
- Cold-start tolerance: Serverless GPU works better when traffic is spiky and startup delay is acceptable. It works less well when large models make every cold start expensive in time and performance.
- Runtime control: Some platforms are better for managed model APIs, while others are better for teams that need custom containers, exact dependencies, or deeper control over the serving stack.
- Scaling behavior: Autoscaling claims can hide meaningful differences in queueing, concurrency handling, scale-down timing, and the operational tooling available around the endpoint.
- Pricing posture: Pay-per-use pricing is attractive when idle time is real. Once requests become steady, the cost advantage can narrow quickly.
- What happens after serverless: Some workloads start as bursty inference and later need a warmer, more repeatable deployment path. That transition matters when choosing a platform early.
Best Serverless GPU Clouds to Compare Right Now

RunPod
- Best for: teams that want a familiar AI-infrastructure path with a clear serverless product and a broader GPU-cloud ecosystem behind it.
- Why consider it: RunPod Serverless is positioned around pay-as-you-go GPU execution, automatic scaling, and developer-friendly deployment for model-backed endpoints.
- Watch out for: teams still need to judge whether the serverless path is really better than a more persistent configuration once traffic or startup overhead becomes steady.
Modal
- Best for: developers who want a code-first platform with autoscaling containers and strong Python-centric ergonomics.
- Why consider it: Modal is often appealing when the team wants serverless compute to feel programmable rather than dashboard-first.
- Watch out for: a strong general serverless abstraction is not automatically the same thing as the best fit for every production inference workload.
Replicate
- Best for: teams that want a fast path from custom model code to a callable API deployment.
- Why consider it: Replicate emphasizes pushing your model, generating an API server, and scaling deployments without owning the infrastructure layer directly.
- Watch out for: convenience is valuable, but teams with deeper runtime or infra requirements may still want more explicit control than a convenience-first path provides.
Baseten
- Best for: teams leaning toward production inference and wanting autoscaling, observability, and a more operations-aware deployment layer.
- Why consider it: Baseten puts strong emphasis on deployment controls, scale-to-zero behavior, production replicas, and real-time performance visibility.
- Watch out for: it is better to treat Baseten as a production inference platform comparison than as a generic "best for everyone" serverless answer.
Beam
- Best for: teams that like code-defined cloud deployment, fast API creation from containers, and flexible serverless GPU execution.
- Why consider it: Beam highlights instant deployment of Docker-based services, autoscaling, millisecond billing, and support for GPU-backed endpoints.
- Watch out for: teams should confirm whether they want Beam's code-and-container style of operation or a more specialized inference-first platform.
fal
- Best for: highly API-driven AI products that care about autoscaling, GPU choice, and a strong serverless story for custom apps or media-generation workloads.
- Why consider it: fal frames Serverless around scaling from zero to large fleets, pay-per-use economics, and support for custom models, apps, and workflows.
- Watch out for: fal also has a separate Compute path for dedicated workloads, which is a reminder that even strong serverless platforms still need a "when not to use serverless" boundary.
Where RunC Fits for Cost-Sensitive Teams
RunC fits this shortlist best when cost control matters and serverless is only one stage of the deployment path. The current platform combines Serverless GPU (Preview), GPU Pods, fast startup, and Shared Network Volumes, which makes it easier to move between burst-mode serving and a warmer, more persistent setup.
One common failure mode is choosing a serverless platform as if the workload will stay bursty forever. Many teams start with event-driven inference, then discover that the same model, weights, and dependencies need a warmer and more repeatable environment. That is where RunC becomes more useful: the platform can still fit when traffic moves from occasional spikes toward something closer to a persistent serving loop.
Serverless GPU is still presented publicly as Preview, so RunC fits best as a shortlist option for teams that care about price sensitivity, deployment flexibility, and a clean path from burst-mode serving into a Pod-based setup.
Which Serverless GPU Cloud Is Best for Different Team Types
- RunPod: a strong starting point for teams that want a familiar serverless GPU workflow and a broader infrastructure ecosystem behind it.
- Modal: a better fit when code-first deployment and programmable infrastructure matter more than a packaged model-service path.
- Replicate: a faster shortlist option when the priority is simple deployment of custom model APIs with less direct infrastructure ownership.
- Baseten: stronger when the workload already looks closer to production inference and needs more explicit deployment operations, autoscaling behavior, and monitoring.
- Beam: more interesting for teams that prefer cloud deployment defined in code and want flexible containerized endpoints.
- fal: worth comparing when the workload is highly API-driven, media-heavy, and closely tied to autoscaling custom AI apps.
- RunC: strongest when cost discipline matters and the likely path is bursty serving first, then a move toward more persistent GPU capacity later.
When Serverless GPU Is the Wrong Choice
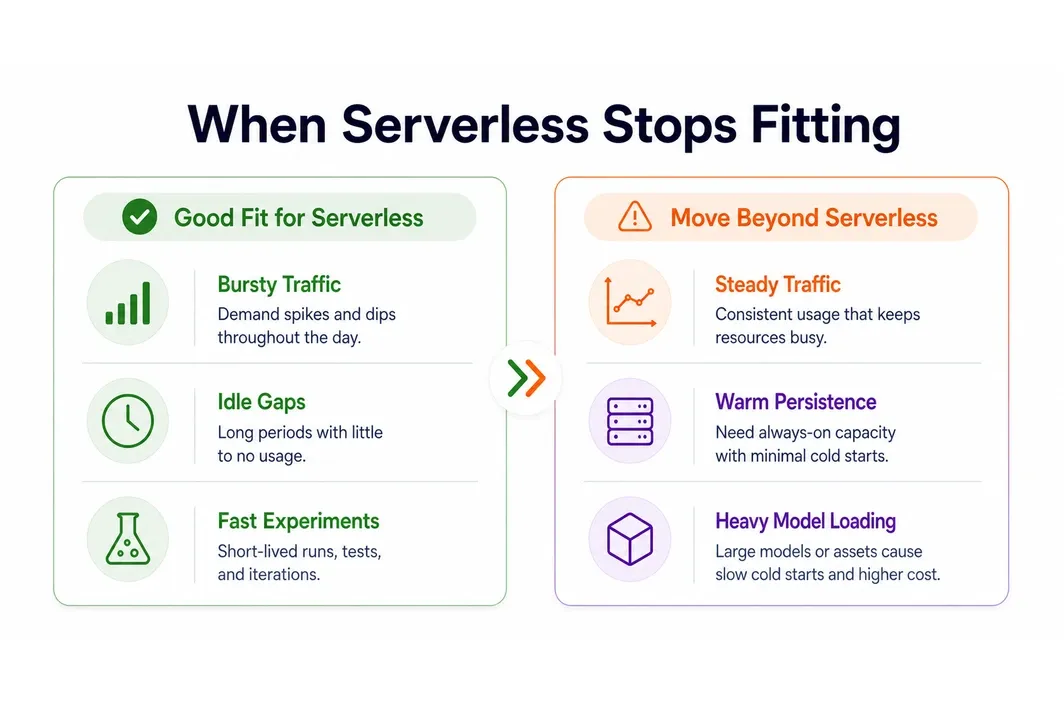
Serverless GPU is not automatically the best answer just because it sounds efficient. It becomes a weaker fit when the service is effectively busy all day, when model loading dominates latency, or when the team keeps paying the same setup cost over and over for a workload that already behaves like a persistent system.
The first warning sign is steady traffic. If your endpoint is always active, zero-idle billing stops being the main story and operational continuity starts to matter more. The second warning sign is warm-state dependence. If you keep reusing the same environment, caches, or model weights, a Pod or dedicated deployment can be operationally cleaner than restarting from zero.
The third warning sign is heavy model startup. Large models, repeated downloads, or slow container preparation can erase the value of a serverless setup very quickly. This is exactly why some of the strongest platforms in this category also maintain a persistent or dedicated path. The deciding factor is workload fit, not whether serverless sounds more modern.
The same logic applies to RunC. The value is not only having a serverless route, but also having a path into GPU Pods once serverless stops fitting.
FAQ
What is the best serverless GPU cloud for AI inference?
There is no single best answer for every team. RunPod, Modal, Replicate, Baseten, Beam, fal, and RunC all solve slightly different problems. The right choice depends on whether you care most about deployment speed, runtime control, production inference tooling, or the path beyond pure serverless.
Is RunPod better than Modal for serverless inference?
That depends on what you are optimizing for. RunPod is often easier to frame as a direct serverless GPU cloud comparison, while Modal is especially attractive for teams that want a code-first serverless platform. The better choice is the one that matches your deployment style and operational expectations.
When should I choose Replicate, Baseten, or Beam instead of a simpler shortlist favorite?
Choose Replicate when model API convenience matters most, Baseten when production inference operations matter more, and Beam when code-defined container deployment is part of the appeal. Those are different buyer questions even though they all live in the same broad serverless GPU category.
When should I stop using serverless GPU and move to Pods or a persistent deployment?
Move when traffic is steady, warm persistence matters, or repeated startup cost is becoming the main operational problem. That is usually the point where a Pod-style environment becomes easier to justify than strict scale-to-zero serving.
Conclusion
The best serverless GPU clouds in 2026 are not the ones with the loudest generic scaling claim. They are the ones that match the actual shape of your inference workload. If you want a shortlist, start by comparing RunPod, Modal, Replicate, Baseten, Beam, and fal against your own cold-start tolerance, runtime control needs, and expected traffic pattern.
Then ask the more durable question: if this workload stops being purely bursty, what happens next? That is where RunC.ai becomes a meaningful comparison. You can evaluate the current Serverless GPU (Preview) direction for event-driven serving, and if the workload matures into something warmer and more repeatable, move into GPU Pods without throwing away the broader platform logic.

Member discussion: